A Simple ETL Pipeline Automation Using Airflow on AWS
How to Extract and Transform Weather Data with Airflow


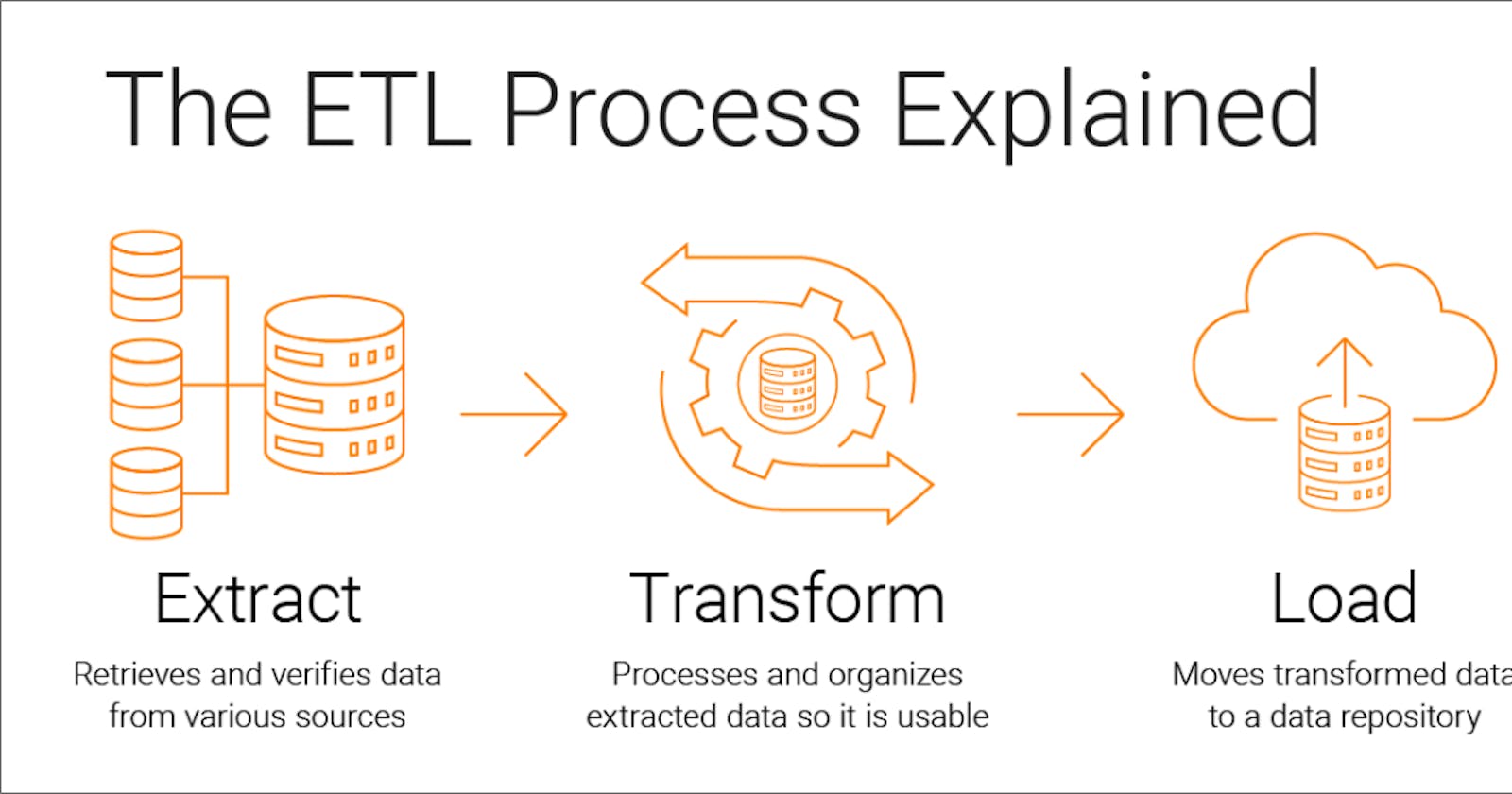
Airflow is an open-source platform for creating, scheduling, and monitoring workflows. In this tutorial, we'll use Airflow to extract weather data from an API, transform the data, and load it into a CSV file in an S3 bucket.
We'll start by creating a new DAG in Airflow. A DAG (Directed Acyclic Graph) is a collection of tasks that are arranged in a way that reflects their dependencies and the order in which they should be executed. In our case, we'll create a DAG that has three tasks: a sensor task to check if the weather API is ready, a task to extract weather data from the API, and a task to transform and load the data into an S3 bucket.
from airflow import DAG
from datetime import timedelta, datetime
from airflow.providers.http.sensors.http import HttpSensor
import json
from airflow.providers.http.operators.http import SimpleHttpOperator
from airflow.operators.python import PythonOperator
import pandas as pd
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'start_date': datetime(2023, 1, 8),
'email': ['myemail@domain.com'],
'email_on_failure': False,
'email_on_retry': False,
'retries': 2,
'retry_delay': timedelta(minutes=2)
}
with DAG('weather_dag',
default_args=default_args,
schedule_interval = '@daily',
catchup=False) as dag:
In the above code block, we import the necessary modules and define the default arguments for our DAG. We set the owner to "airflow", the start date to January 8, 2023, and the schedule interval to daily. We also set up email notifications for failures and retries.
Next, we'll define the tasks in our DAG. The first task is a sensor task that checks if the weather API is ready:
is_weather_api_ready = HttpSensor(
task_id ='is_weather_api_ready',
http_conn_id='weathermap_api',
endpoint='/data/2.5/weather?q=Portland&APPID=5031cde3d1a8b9469fd47e998d7aef79'
)
This task uses the HttpSensor operator to check if the weather API is ready. We specify the http_conn_id as "weathermap_api" to use the connection details we've set up in Airflow. We also specify the endpoint to check, which is the API endpoint for Portland weather data.
The second task is a simple HTTP operator that extracts weather data from the API:
extract_weather_data = SimpleHttpOperator(
task_id = 'extract_weather_data',
http_conn_id = 'weathermap_api',
endpoint='/data/2.5/weather?q=Portland&APPID=5031cde3d1a8b9469fd47e998d7aef79',
method = 'GET',
response_filter= lambda r: json.loads(r.text),
log_response=True
)
This task uses the SimpleHttpOperator to extract weather data. We specify the http_conn_id and endpoint as before and also specify the HTTP method as GET. We use a lambda function to parse the JSON response from the API and log the response for debugging purposes.
The third task is a Python Operator that transforms and loads the weather data into an S3 bucket:
def kelvin_to_fahrenheit(temp_in_kelvin):
temp_in_fahrenheit = (temp_in_kelvin - 273.15) * (9/5) + 32
return temp_in_fahrenheit
def transform_load_data(task_instance):
data = task_instance.xcom_pull(task_ids="extract_weather_data")
city = data["name"]
weather_description = data["weather"][0]['description']
temp_farenheit = kelvin_to_fahrenheit(data["main"]["temp"])
feels_like_farenheit= kelvin_to_fahrenheit(data["main"]["feels_like"])
min_temp_farenheit = kelvin_to_fahrenheit(data["main"]["temp_min"])
max_temp_farenheit = kelvin_to_fahrenheit(data["main"]["temp_max"])
pressure = data["main"]["pressure"]
humidity = data["main"]["humidity"]
wind_speed = data["wind"]["speed"]
time_of_record = datetime.utcfromtimestamp(data['dt'] + data['timezone'])
sunrise_time = datetime.utcfromtimestamp(data['sys']['sunrise'] + data['timezone'])
sunset_time = datetime.utcfromtimestamp(data['sys']['sunset'] + data['timezone'])
transformed_data = {"City": city,
"Description": weather_description,
"Temperature (F)": temp_farenheit,
"Feels Like (F)": feels_likeGreat! Here's the rest of the tutorial article:
_farenheit,
"Minimun Temp (F)":min_temp_farenheit,
"Maximum Temp (F)": max_temp_farenheit,
"Pressure": pressure,
"Humidty": humidity,
"Wind Speed": wind_speed,
"Time of Record": time_of_record,
"Sunrise (Local Time)":sunrise_time,
"Sunset (Local Time)": sunset_time
}
transformed_data_list = [transformed_data]
df_data = pd.DataFrame(transformed_data_list)
aws_credentials = {"key": "xxxxxxxxx", "secret": "xxxxxxxxxx", "token": "xxxxxxxxxxxxxx"}
now = datetime.now()
dt_string = now.strftime("%d%m%Y%H%M%S")
dt_string = 'current_weather_data_portland_' + dt_string
df_data.to_csv(f"s3://weatherapiairflowyoutubebucket-yml/{dt_string}.csv", index=False, storage_options=aws_credentials)
transform_load_weather_data = PythonOperator(
task_id= 'transform_load_weather_data',
python_callable=transform_load_data
)
This task defines a function kelvin_to_fahrenheit that converts temperature from Kelvin to Fahrenheit. The transform_load_data function is the main function that transforms and loads the weather data. It uses the xcom_pull method to get the data from the previous task, extracts the relevant data, converts the temperature to Fahrenheit using the kelvin_to_fahrenheit function, and creates a dictionary of transformed data. It then converts the dictionary to a Pandas DataFrame, sets up AWS credentials, and saves the DataFrame to an S3 bucket.
Finally, we'll define the dependencies between the tasks:
is_weather_api_ready >> extract_weather_data >> transform_load_weather_data
This code sets up the dependencies between the tasks. The is_weather_api_ready task must complete successfully before the extract_weather_data task can run. Similarly, the extract_weather_data task must complete successfully before the transform_load_weather_data task can run.
That's it! We've created a DAG that extracts weather data from an API, transforms the data, and loads it into an S3 bucket. You can use this as a starting point to build more complex workflows in Airflow.
Cover photo from Analytics Vidhya