How are training and tuning different?

I'm a passionate writer and practitioner in the field of machine learning in production. With a strong background in both machine learning and software engineering, I bring a unique perspective to the challenges and intricacies of deploying machine learning models in real-world environments.
Machine learning models are prepared in two steps: training and tuning. We can distinguish these processes by what they're affecting. Let's take a look at what a machine-learning algorithm is. A machine learning algorithm tries to capture what happens in the real world in the form of a mathematical equation.
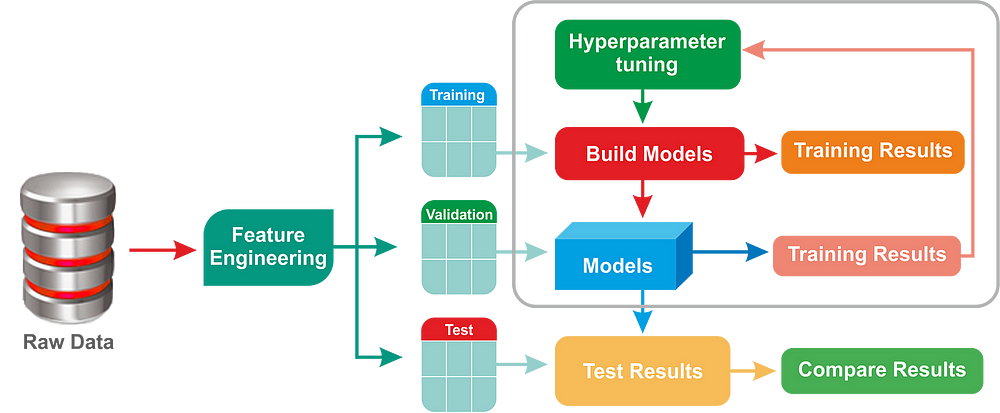
This equation has unknown values called parameters that the algorithm is trying to estimate. There are multiple different ways to estimate these values (which are called algorithms) Algorithms try to achieve the same thing but with a different approach and they all have different hyper parameters. We can think of hyperparameters as the settings of the machine learning algorithm. When you first set up an ML algorithm, you set up the hyperparameter values based on what you believe would result in good performance. This is sometimes based on research and sometimes on experience. After the hyperparameter values are set and the data is ready, we train the model on the training dataset, and this is called training. During this process, the hyperparameter values stay the same, but the parameters are updated. This is sometimes also referred to as learning. After the training is done, sometimes the resulting model might not be good enough because the hyperparameters of the model do not have their optimal value for this particular problem.

When this is the case, you might want to take on another step, which is tuning. In this step, you will try on a bunch of different combinations of hyperparameter settings to try to find the best one. The number of different combinations can grow really quickly. For example, if you have five hyperparameters and each has five possible values, you have 25 different models to train and test. Instead of trying out all possible combinations, which is called grid search, you can employ smarter ways to find the best hyperparameter values to save time.



