MLOps Infrastructure Stack
Tech stack and tooling for MLOps

I'm a passionate writer and practitioner in the field of machine learning in production. With a strong background in both machine learning and software engineering, I bring a unique perspective to the challenges and intricacies of deploying machine learning models in real-world environments.
To bring any machine learning model to fruition, an abundance of experimentation cycles is required to ascertain the optimal ML model that will effectively achieve the desired business objective. This phase of experimentation introduces a heightened level of intricacy to any ML project, as it encompasses three key components: Data, Model, and Code. To navigate this labyrinthine complexity, we must employ well-defined structures, processes, and sophisticated software tools that are capable of managing ML artefacts and overseeing the machine-learning cycle in its entirety.
MLOps must be language-, framework-, platform-, and infrastructure-agnostic practice. MLOps should follow a “convention over configuration” implementation.
The MLOps technology stack should include tooling for the following tasks:
data engineering,
version control (of data, ML models and code),
CI/CD pipelines,
automating deployments and experiments,
model performance assessment, and
model monitoring in production.
To tackle the multifaceted obstacles inherent to MLOps, one is presented with a lot of possibilities to choose from. These options range from leveraging a readily available machine-learning platform to constructing an in-house solution by integrating open-source libraries. Prominent cloud providers such as Google Cloud, AWS, and AzureML are already hard at work developing machine learning platforms like AI Platform, SageMaker, and AzureML, respectively. The Kubeflow project, which originated at Google, provides a prime option for managing an array of open-source tools tailored to MLOps needs and aggregating them on Kubernetes. The adoption of such an ML platform is contingent upon the cloud strategy of the organization in question. If an organization prefers to opt for an in-house solution, then non-cloud systems such as MLFlow, Sacred, or DVC might serve as the optimal tool of choice.
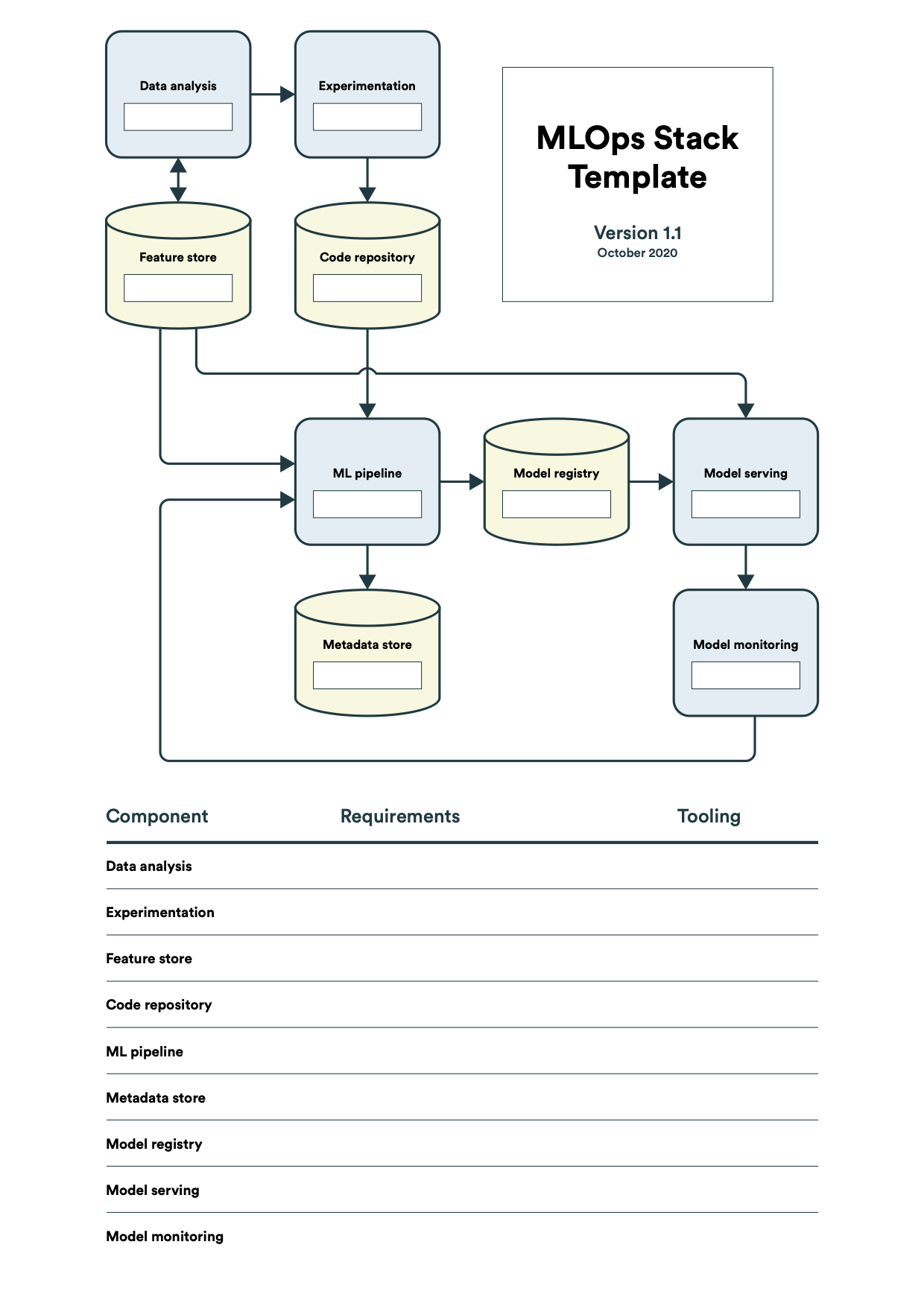
At present, the ever-changing realm of MLOps technologies remains in a constant state of flux. Given that the scope of each tool often spans various components of the MLOps process, it is crucial to consider the MLOps tech stack for every use case. For instance, the requirements for model versioning and monitoring may differ based on the specific use case. The monitoring of models in highly regulated industries such as finance or medicine demands a more sophisticated approach than in non-regulated fields. To ensure a structured approach when selecting the MLOps tech stack, one can rely on the MLOps Stack Template. This comprehensive template breaks down a machine learning workflow into nine components, as outlined in the MLOps Principles. Before settling on any particular tools or frameworks, one must gather and analyze the corresponding requirements for each component. Only then can tool selection be aligned with the results of this analysis.
The below Stack Template is courtesy of Henrik Skogström (Valohai)
An example of the technology stack might include the following open-source tools:
| MLOps Setup Components | Tools |
| Data Analysis | Python with its libraries for DA |
| Source Control | Git |
| Test and Build Services | PyTest and Make |
| Deployment Services | Git, DVC |
| Model and Dataset Registry | DVC[aws s3] |
| Feature Store | Project code library |
| ML Metadata Store | DVC |
| ML Pipeline Orchestrator | DVC & Make |
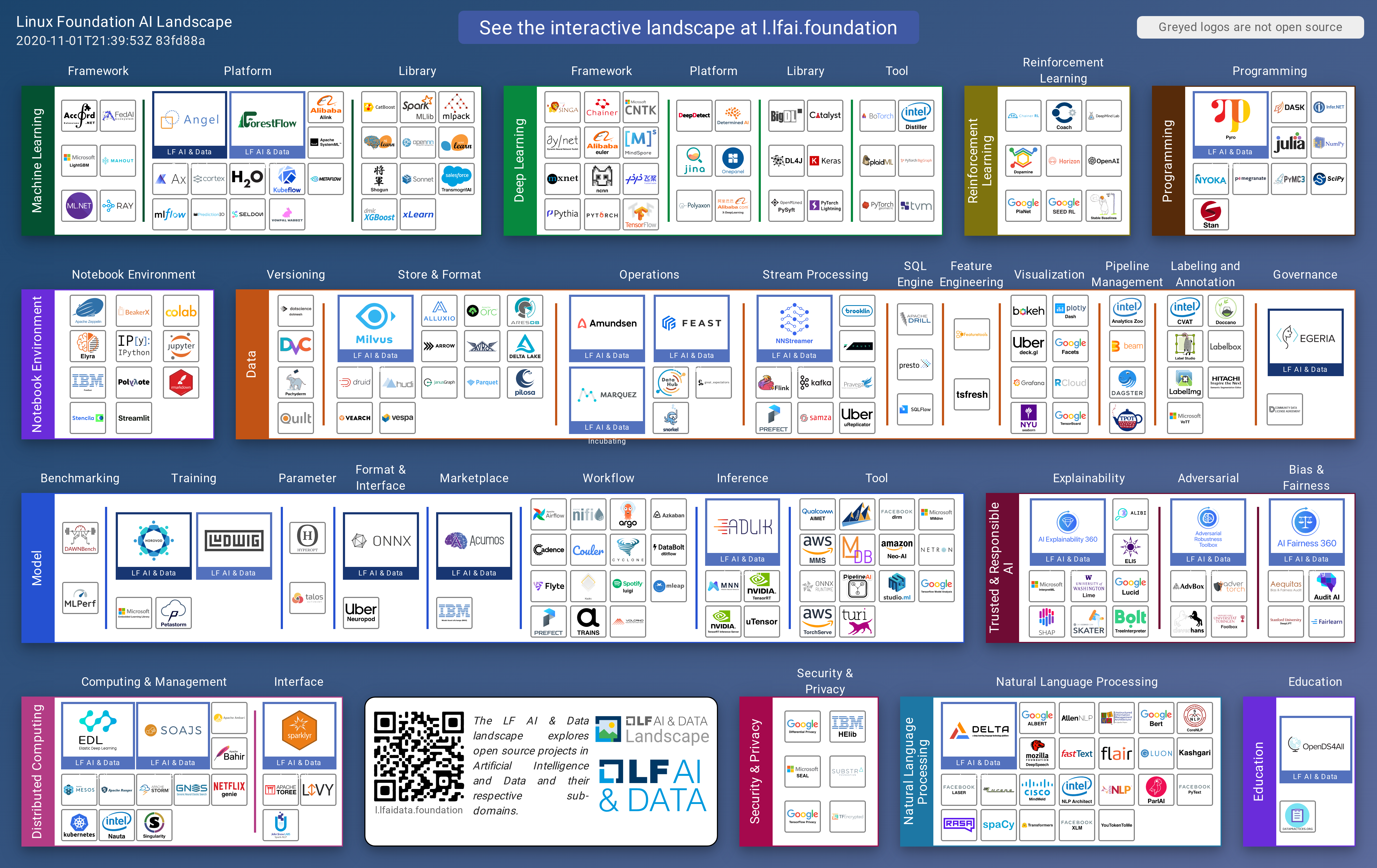
Organizations may choose to craft their very own in-house MLOps system by amalgamating pre-existing open-source libraries, contingent on their requirements and restrictions. However, to construct such a system, one must possess a thorough understanding of the MLOps tool landscape. This landscape is in a constant state of flux, with new tools still emerging, each specializing in a distinct niche. To offer clarity on this ever-evolving field, the Linux Foundation's LF AI project has developed a sophisticated visualization for ML/AI and MLOps tools. In addition to this, a meticulously curated list of production machine learning tools is also maintained by the Institute for Ethical AI.